I got this interesting grant from Igor Carron, the master of compressed sensing.
Google has a new grant program: Exascale which gives tens of millions of core hours for scientific computing guys. Anyone interested?
Monday, May 30, 2011
Thursday, May 26, 2011
Label propagation: should one use GraphLab or Hadoop?
I got a question today from Mike Khristo , who is working on building a collaborative filtering engine, about implementing label propagation in GraphLab. Label propagation is rather a simple algorithm for ranking items, see a nice tutorial I got from Mike: http://skillsmatter.com/
The algorithm is very simple to implement in GraphLab. One of our GraphLab users, Akshay Bat, a Cornell graduate student, donated his implementation. He tested the algorithm using 40M Twitter users.
Specifically, we got the following feedback:
If anyone else is using label propagation with GraphLab I would love to know!
The algorithm is very simple to implement in GraphLab. One of our GraphLab users, Akshay Bat, a Cornell graduate student, donated his implementation. He tested the algorithm using 40M Twitter users.
Hadoop implementation of the label propagation algorithm is described on:
GraphLab performance is described on:
http://www.akshaybhat.com/
The GraphLab code is found here: https://gist.github.com/836063
The GraphLab code is found here: https://gist.github.com/836063
Specifically, we got the following feedback:
"The Graphlab implementation is significantly faster than the Hadoop implementation, and requires much less resources.It is extremely efficient for networks with millions of nodes and billions of edges, as shown by its performance on the Twitter Social network from June 2009.I haven't yet come across any other implementation or a paper describing an implementation of community detection algorithm which can scale for such large networks."
- Akshay BhatIf anyone else is using label propagation with GraphLab I would love to know!
Monday, May 23, 2011
SVD++ Koren's collaborative filtering algorithm implemented in GraphLab
Due to many user requests, I have implemented Yehuda Koren's SVD++ collaborative filtering algorithm in GraphLab. Thanks to Nicholas Ampazis, and to Yehuda Koren who supplied his C++ version.
Implementation is based on the paper: Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model by Yehuda Koren.
Note that unlike the original paper, our implementation is parallel, thus exploiting multiple cores whenever they are available.
Here are some timing results of the multicore implemenation:
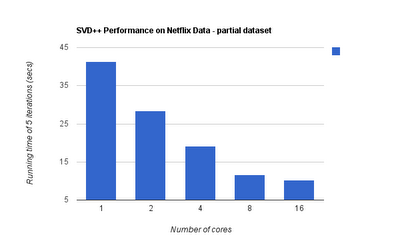 (I used 8 core machine, 5 SVD++ iterations using Netflix partial dataset with 3M ratings)
(I used 8 core machine, 5 SVD++ iterations using Netflix partial dataset with 3M ratings)
Here are some accuracy results:
 It seems that additional cores improve accuracy.
It seems that additional cores improve accuracy.
The way to run SVD++ is to
0) Istall GraphLab based on the instructions: http://graphlab.org/download.html
1) Run with run mode = 5
Example:
./pmf netflix 5 --ncpus=XX --scheduler="round_robin(max_iterations=10)"
Two other options are --minval=XX and --maxval=XX
for kddcup, it should be --minval=0 and --maxval=100
(if file name is kddcup it will automatically set those values).
For Netflix data, it should be --minval=1 and --maxval=5
Example run on the full Netflix dataset (using 8 cores:)
Implementation is based on the paper: Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model by Yehuda Koren.
Note that unlike the original paper, our implementation is parallel, thus exploiting multiple cores whenever they are available.
Here are some timing results of the multicore implemenation:

Here are some accuracy results:

The way to run SVD++ is to
0) Istall GraphLab based on the instructions: http://graphlab.org/download.html
1) Run with run mode = 5
Example:
./pmf netflix 5 --ncpus=XX --scheduler="round_robin(max_iterations=10)"
Two other options are --minval=XX and --maxval=XX
for kddcup, it should be --minval=0 and --maxval=100
(if file name is kddcup it will automatically set those values).
For Netflix data, it should be --minval=1 and --maxval=5
Example run on the full Netflix dataset (using 8 cores:)
<55|0>bickson@biggerbro:~/newgraphlab/graphlabapi/release/demoapps/pmf$ ./pmf netflix-r 5 --ncpus=8 --scheduler=round_robin INFO: pmf.cpp(main:1081): PMF/ALS Code written By Danny Bickson, CMU Send bug reports and comments to danny.bickson@gmail.com WARNING: pmf.cpp(main:1083): Code compiled with GL_NO_MULT_EDGES flag - this mode does not support multiple edges between user and movie in different times WARNING: pmf.cpp(main:1086): Code compiled with GL_NO_MCMC flag - this mode does not support MCMC methods. WARNING: pmf.cpp(main:1089): Code compiled with GL_SVD_PP flag - this mode only supports SVD++ run. Setting run mode SVD_PLUS_PLUS INFO: pmf.cpp(main:1126): SVD_PLUS_PLUS starting loading data file netflix-r Loading netflix-r TRAINING Matrix size is: USERS 480189 MOVIES 17770 TIME BINS 27 Creating 99072112 edges (observed ratings)... ................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................loading data file netflix-re Loading netflix-re VALIDATION Matrix size is: USERS 480189 MOVIES 17770 TIME BINS 27 Creating 1408395 edges (observed ratings)... ........loading data file netflix-rt Loading netflix-rt TEST skipping file setting regularization weight to 1 PTF_ALS for matrix (480189, 17770, 27):99072112. D=20 pU=1, pV=1, pT=1, muT=1, D=20 nuAlpha=1, Walpha=1, mu=0, muT=1, nu=20, beta=1, W=1, WT=1 BURN_IN=10 SVD++ 20 factors (rate=8.00e-03, reg=1.50e-02) complete. Obj=6.8368e+08, TRAIN RMSE=3.7150 VALIDATION RMSE=3.7946. max iterations = 0 step = 1 max_iterations = 0 INFO: asynchronous_engine.hpp(run:94): Worker 0 started. INFO: asynchronous_engine.hpp(run:94): Worker 2 started. INFO: asynchronous_engine.hpp(run:94): Worker 1 started. INFO: asynchronous_engine.hpp(run:94): Worker 3 started. INFO: asynchronous_engine.hpp(run:94): Worker 4 started. INFO: asynchronous_engine.hpp(run:94): Worker 5 started. INFO: asynchronous_engine.hpp(run:94): Worker 6 started. INFO: asynchronous_engine.hpp(run:94): Worker 7 started. Entering last iter with 1 92.7115) Iter SVD 1, TRAIN RMSE=1.0587 VALIDATION RMSE=0.9892. Entering last iter with 2 174.441) Iter SVD 2, TRAIN RMSE=0.9096 VALIDATION RMSE=0.9536. Entering last iter with 3 260.442) Iter SVD 3, TRAIN RMSE=0.8678 VALIDATION RMSE=0.9805. Entering last iter with 4 321.652) Iter SVD 4, TRAIN RMSE=0.8480 VALIDATION RMSE=0.9603. Entering last iter with 5 388.735) Iter SVD 5, TRAIN RMSE=0.8291 VALIDATION RMSE=0.9312. Entering last iter with 6 470.291) Iter SVD 6, TRAIN RMSE=0.8106 VALIDATION RMSE=0.9264. Entering last iter with 7 558.886) Iter SVD 7, TRAIN RMSE=0.8046 VALIDATION RMSE=0.9270. Entering last iter with 8 628.846) Iter SVD 8, TRAIN RMSE=0.8007 VALIDATION RMSE=0.9242. Entering last iter with 9 687.212) Iter SVD 9, TRAIN RMSE=0.7969 VALIDATION RMSE=0.9221. Entering last iter with 10 775.021) Iter SVD 10, TRAIN RMSE=0.7926 VALIDATION RMSE=0.9215. Entering last iter with 11 836.143) Iter SVD 11, TRAIN RMSE=0.7907 VALIDATION RMSE=0.9203. Entering last iter with 12 919.416) Iter SVD 12, TRAIN RMSE=0.7874 VALIDATION RMSE=0.9195. Entering last iter with 13 1000.87) Iter SVD 13, TRAIN RMSE=0.7852 VALIDATION RMSE=0.9191. Entering last iter with 14 1081.9) Iter SVD 14, TRAIN RMSE=0.7834 VALIDATION RMSE=0.9186. Entering last iter with 15 1169.46) Iter SVD 15, TRAIN RMSE=0.7817 VALIDATION RMSE=0.9182. Entering last iter with 16 1236.61) Iter SVD 16, TRAIN RMSE=0.7808 VALIDATION RMSE=0.9179. Entering last iter with 17 1304.72) Iter SVD 17, TRAIN RMSE=0.7795 VALIDATION RMSE=0.9176. Entering last iter with 18 1366.15) Iter SVD 18, TRAIN RMSE=0.7783 VALIDATION RMSE=0.9173. Entering last iter with 19 1453.8) Iter SVD 19, TRAIN RMSE=0.7768 VALIDATION RMSE=0.9172. Entering last iter with 20 1521.15) Iter SVD 20, TRAIN RMSE=0.7763 VALIDATION RMSE=0.9171. Entering last iter with 21 1588.85) Iter SVD 21, TRAIN RMSE=0.7754 VALIDATION RMSE=0.9175. Entering last iter with 22 1654.52) Iter SVD 22, TRAIN RMSE=0.7757 VALIDATION RMSE=0.9170. Entering last iter with 23 1722.88) Iter SVD 23, TRAIN RMSE=0.7740 VALIDATION RMSE=0.9171. Entering last iter with 24 1783.94) Iter SVD 24, TRAIN RMSE=0.7739 VALIDATION RMSE=0.9163.
Friday, May 20, 2011
Large scale logistic regression
L1 regularized logistic regression is one of the widely used applied machine learning algorithms. Recently I attended an interesting talk by Rajat Raina from Facebook, who is working on both ad placement and new friends recommendation. It seems that Facebook is using logistic regression for ranking which ads to display. I also talked to Abhinav Gputa, co-Founder of RocketFuel, a successful Bay area startup that optimizes ads placement. RocketFuel is also using logistic regression for ranking ads. I further hear that Google is using it as well in Gmail ad placement.
A related problem domain to L1 regularization is compressed sensing - a great resource to learn about compressed sensing is found in Igor Caroon's blog. In the ML community, this problem is called also LASSO.
So why is logistic regression widely used? Some of the reasons are that it rather simple to compute, since it represent a convex optimization problem, that has a global unique minimum. However, when the problem size becomes large, it becomes harder and harder to efficiently compute it. Our new paper Parallel Coordinate Descent for L1-Regularized Loss Minimization (to appear on this year ICML ) gives some insight about how to compute large scale L1 regularized loss efficiently on large scale problems.
As an executive summary, I summarize below our experience in computing large scale logistic regression below. For medium size problems (problem that fit in Matlab), Kim and Boyd interior point method outperforms other algorithms, both in accuracy and speed. It is further robust and converges well on many datasets. Unfortunately, interior point methods do not scale well for large data sets, since they involve the computation of the Hessian, which is quadratic in the number of variables.
I believe that there are two possible approaches for tackling the computational problem on large datasets (i.e. problems that do not fit into a memory of one machine). One of them is our new Shotgun algorithm which works by parallelising iterative coordinate descent (the shooting algorithm). Other useful approach is parallel stochastic gradient descent. The drawback is the L1 sparsity is not obtained using the gradient descent and thus small values have to be truncated to zero.
A related problem domain to L1 regularization is compressed sensing - a great resource to learn about compressed sensing is found in Igor Caroon's blog. In the ML community, this problem is called also LASSO.
So why is logistic regression widely used? Some of the reasons are that it rather simple to compute, since it represent a convex optimization problem, that has a global unique minimum. However, when the problem size becomes large, it becomes harder and harder to efficiently compute it. Our new paper Parallel Coordinate Descent for L1-Regularized Loss Minimization (to appear on this year ICML ) gives some insight about how to compute large scale L1 regularized loss efficiently on large scale problems.
As an executive summary, I summarize below our experience in computing large scale logistic regression below. For medium size problems (problem that fit in Matlab), Kim and Boyd interior point method outperforms other algorithms, both in accuracy and speed. It is further robust and converges well on many datasets. Unfortunately, interior point methods do not scale well for large data sets, since they involve the computation of the Hessian, which is quadratic in the number of variables.
I believe that there are two possible approaches for tackling the computational problem on large datasets (i.e. problems that do not fit into a memory of one machine). One of them is our new Shotgun algorithm which works by parallelising iterative coordinate descent (the shooting algorithm). Other useful approach is parallel stochastic gradient descent. The drawback is the L1 sparsity is not obtained using the gradient descent and thus small values have to be truncated to zero.
Friday, May 13, 2011
RecLab Prize on Overstock.com - 1M$
As if MLers where not busy with the Yahoo! KDD Cup, today I found out about another interesting contest.
This time the prize is much higher: up to 1M$. See http://overstockreclabprize.com/
Jake Mannix (from Twitter) dug into the details and here is his impression:
It's actually a pretty interesting challenge, once you get past the
constrictions of their API: you're optimizing explicitly for revenue-per-session, take as
input past sessions, which include the kinds of practical things you'd like: each
session is by a userId which will naturally include repeat customers,
products have prices, and there are categoryId labels already.
Due to the whole Netflix data lawsuit, the training data is synthetic, which
puts the contestants at a disadvantage, and another interesting fact:
runtime performance is at issue: your code will be run *live*, with your model being
used to produce recommendations with a hard timeout of 50ms - if you
miss this more than 20% of the time, you fail to progress to the end of
the semi-final round.
You're allowed to use open-source Apache licensed code (and are in fact
*required* to license your code according to the ASL to compete), but
their APIs are, while extraordinarily similar to Hadoop and Mahout/Taste,
are fixed, so you can't just do drop-in replacement.
This time the prize is much higher: up to 1M$. See http://overstockreclabprize.com/
Jake Mannix (from Twitter) dug into the details and here is his impression:
It's actually a pretty interesting challenge, once you get past the
constrictions of their API: you're optimizing explicitly for revenue-per-session, take as
input past sessions, which include the kinds of practical things you'd like: each
session is by a userId which will naturally include repeat customers,
products have prices, and there are categoryId labels already.
Due to the whole Netflix data lawsuit, the training data is synthetic, which
puts the contestants at a disadvantage, and another interesting fact:
runtime performance is at issue: your code will be run *live*, with your model being
used to produce recommendations with a hard timeout of 50ms - if you
miss this more than 20% of the time, you fail to progress to the end of
the semi-final round.
You're allowed to use open-source Apache licensed code (and are in fact
*required* to license your code according to the ASL to compete), but
their APIs are, while extraordinarily similar to Hadoop and Mahout/Taste,
are fixed, so you can't just do drop-in replacement.
Subscribe to:
Posts (Atom)