I am one of the readers of your weblog. I have a question about one of your posts in your weblog about comparison of of two linear algebra libraries: 'it++ vs eigen" ; I guess you are the expert person who can answer my question.
I have an algorithm that involves matrix-matrix and matrix-vector matrix multiplication iteratively and involves all kinds of dense and sparse matrices and vectors. I have implemented my algorithm using gmm with atlas flag active but it seems that it is still slower than MATLAB. More specifically, it seems that gmm uses one thread comparing to MATLAB that uses multiple threads when it is compiled with MCC.
I was wondering if any of those libraries you have introduced in your post (it++, eigen) are capable to of multi-threading and how does it compared with MATLAB linear algebra engine.
Regards,
Kayhan
It is always nice to get feedback from my readers! Especially the ones who call
me an expert (although without "I guess" - next time please!! :-)
There is definitely a room for improving blas/lapack performance. Need to dig into the details of the library you are using.
Eigen has some nice benchmarks here:
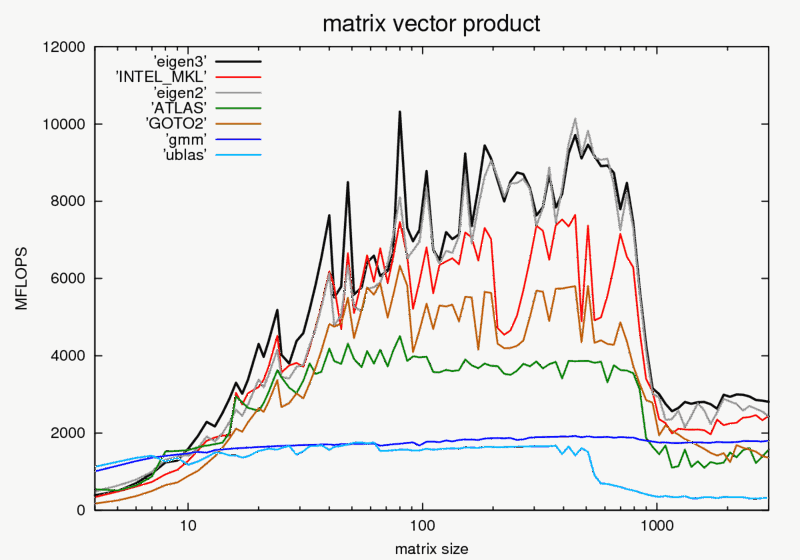
As you can see, Atlas has relatively inferior performance vs. Eigen and
Intel MKL.(Higher MFLOPS is better).
Here is an example setup for Intel MKL I got from Joel Welling (PSC):
I'm guessing that the current configuration produces too many threads,
or puts those threads in the wrong places. See for example the section
'Choosing the number of threads with MKL' on
http://www.psc.edu/general/software/packages/mkl/ . It might also be
worth linking against the non-threaded version of MKL, which I think
would involve doing:
-L${MKL_PATH} -lmkl_intel_ilp64 -lmkl_sequential -lmkl_core -lpthread
instead of:-L${MKL_PATH} -lmkl_intel_lp64 -lmkl_intel_thread -lmkl_core \
-L/opt/intel/Compiler/11.1/072/lib/intel64 -liomp5 -fopenmp
From my experience, there is a huge difference in performance between different lapack configurations on the same machine. For example, on BlackLight supercomputer
I got the following timing results for Alternating least squares on Netflix data.
Here is a graph comparison different implementations. I used 16 BlackLight cores. Alternating least squares is run 10 iterations to factorize a matrix of 100,000,000 nnz. The width of the factor matrices was set to D=30.
As you can see, wrong configuration resulted in x24 more running time! (In this Graph - lower is better!) Overall, if you are using an Intel platform I highly recommend using MKL.
Why don't you try out GraphLab? It is designed for iterative algorithms on sparse data. In case you use it is much easier to deploy efficiently the multiple cores.
that would be "importance" right ?
ReplyDeleteGo to sleep! :-)
ReplyDeleteNow I see you are in Paris? nice!
ReplyDelete